Парсим содержимое сайтов с помощью Google Таблиц. В частности, рассмотрим функции importHTML и importXML. Первую функцию очень удобно использовать если данные находятся в какой-то таблице или списке, а вторая функция является универсальной и практически не имеет ограничений.
Функция importHTML
С помощью функции importHTML можно настроить импорт данных из таблицы или списка на странице сайта.
Синтаксис
=IMPORTHTML(ссылка; запрос; индекс)
- ссылка — ссылка на веб-страницу, включая протокол (http:// или https://),
- запрос — значения «table» или «list», смотря, что нужно парсить (таблицу или список),
- индекс – порядковый номер списка или таблицы (отсчет начинается с 1).
Пример:
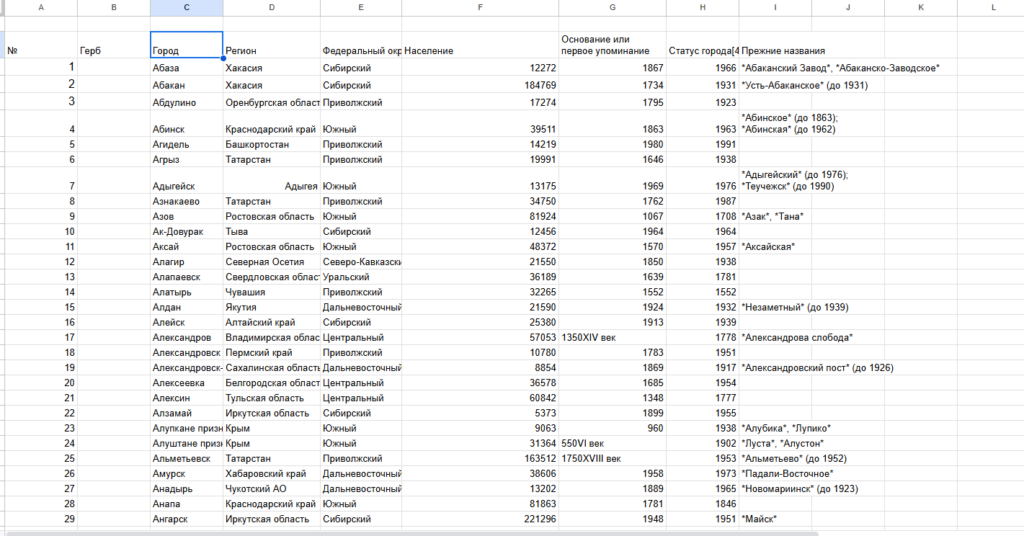
IMPORTHTML("http://ru.wikipedia.org/wiki/Население_Индии"; "table"; 4)
Переменные можно разместить в ячейках, тогда формула изменится так:
IMPORTHTML(A2; B2; C2)
В примере сделано ввиде прямых формул в таблице, я делаю с помощью вызова из меню, к сожалению города эстонии не получается выгрузить буду брать ту ссылку, которая в примере
Чтобы выгрузить данные из этой таблицы нам нужно указать в формуле ее порядковый номер в коде страницы. Чтобы этот номер узнать, нужно открыть код сайта (inspect element)
Выгрузка данных из списка
выгрузить все пункты меню, оформленного тегами
Как и в первом примере для формулы понадобится определить порядковый номер списка в коде сайта
=IMPORTHTML(“https://tools-markets.ru/”;”list”;3)
Функция importXML
С помощью функции importXML можно настроить импорт данных из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML.
По сравнению с importHTML у данной функции гораздо более широкое применение. Она позволяет собирать практически любую информацию со страницы/документа, от частичных фрагментов до полного ее содержания. Ниже будут описаны примеры парсинга HTML-страниц сайта. Парсинг по файлам рассматривать не стану, т.к. такая задача возникает редко и большинство из вас с этим не столкнется никогда. Но если что, принцип работы везде одинаковый, главное понять суть.
Синтаксис
IMPORTXML(ссылка; "//XPath запрос")
- ссылка – адрес веб-страницы с указанием протокола (http:// или https://). Значение этого параметра должно быть заключено в кавычки или представлять собой ссылку на ячейку, содержащую URL страницы.
- //XPath запрос – то, что будем импортировать. Ниже мы разберем основные примеры запросов (а тут подробнее про XPath).
Пример:
IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing"; "//a/@href")
Значения переменных можно хранить в ячейках, тогда формула будет такой:
IMPORTXML(A2; B2)
Импорт мета-тегов и заголовков со страниц
Самая простая и распространенная ситуация, которая может быть — узнать мета-теги или заголовки страниц.
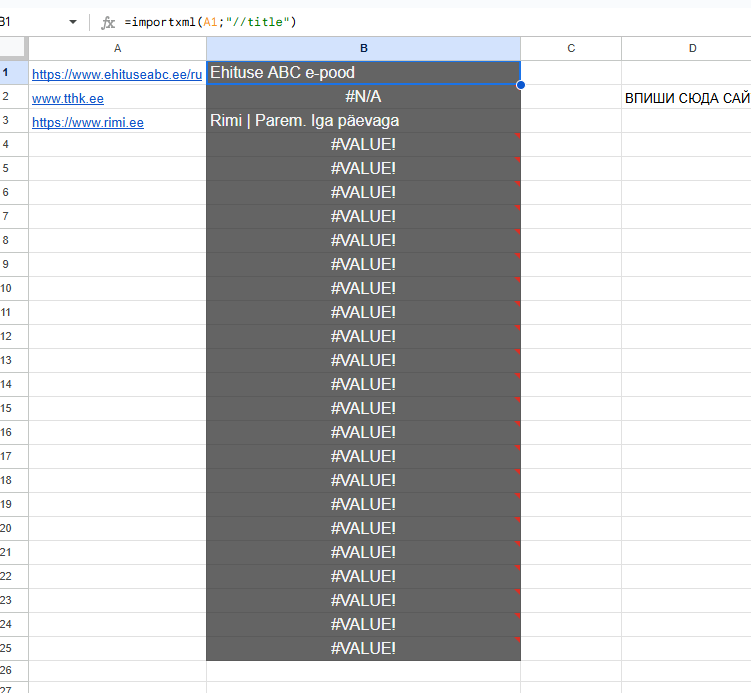
Заголовки по примеру rimi.ee
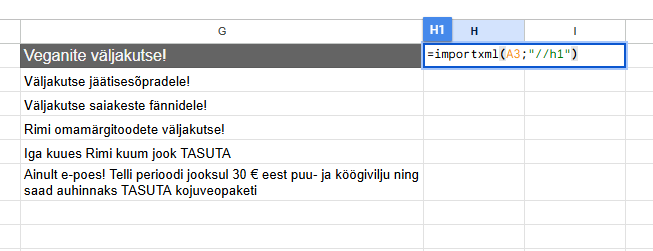
Мета
=importxml(A3;”//meta[@name=’description’]/@content”)
- ищем тег meta //meta
- у которого есть атрибут name=’description’ [@name=’description’]
- и парсим содержимое второго атрибута content /@content

Получение разной ифны с сайтов
Определение языка сайта (по мета-тегу или заголовку)
Получение title страницы
Получение meta description
Проверка наличия Google Analytics / GTM
Извлечение всех ссылок с главной страницы
Проверка, доступен ли сайт (HTTP 200 OK)
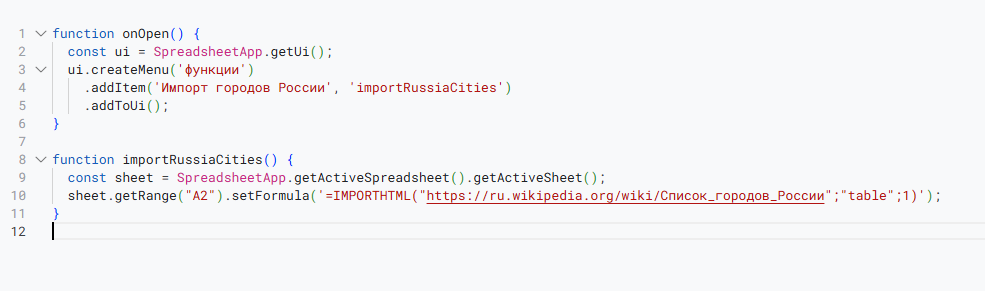
function onOpen() {
const ui = SpreadsheetApp.getUi();
ui.createMenu("Анализ сайта")
.addItem("1. Определить язык сайта", "detectSiteLanguage")
.addItem("2. Получить заголовок (title)", "getPageTitle")
.addItem("3. Получить meta description", "getMetaDescriptionFromURL")
.addItem("4. Проверить доступность сайта", "checkSiteStatus")
.addItem("5. Найти ссылки на странице", "extractAllLinks")
.addToUi();
}
// 1. Определение языка по <html lang="...">
function detectSiteLanguage() {
const url = SpreadsheetApp.getActiveSheet().getRange("A1").getValue();
const html = UrlFetchApp.fetch(url).getContentText();
const match = html.match(/<html[^>]*lang=["']?([a-z\-]+)["']?/i);
const lang = match ? match[1] : "Не найдено";
SpreadsheetApp.getActiveSheet().getRange("B1").setValue("Язык сайта: " + lang);
}
// 2. Получение заголовка страницы
function getPageTitle() {
const url = SpreadsheetApp.getActiveSheet().getRange("A1").getValue();
const html = UrlFetchApp.fetch(url).getContentText();
const match = html.match(/<title>(.*?)<\/title>/i);
const title = match ? match[1] : "Не найден";
SpreadsheetApp.getActiveSheet().getRange("B2").setValue("Title: " + title);
}
// 3. Получение meta description
function getMetaDescriptionFromURL() {
const url = SpreadsheetApp.getActiveSheet().getRange("A1").getValue();
const html = UrlFetchApp.fetch(url).getContentText();
const match = html.match(/<meta\s+name=["']description["']\s+content=["']([^"]+)["']/i);
const desc = match ? match[1] : "Не найдено";
SpreadsheetApp.getActiveSheet().getRange("B3").setValue("Description: " + desc);
}
// 4. Проверка, доступен ли сайт
function checkSiteStatus() {
const url = SpreadsheetApp.getActiveSheet().getRange("A1").getValue();
try {
const response = UrlFetchApp.fetch(url);
const code = response.getResponseCode();
SpreadsheetApp.getActiveSheet().getRange("B4").setValue("Статус: " + code);
} catch (e) {
SpreadsheetApp.getActiveSheet().getRange("B4").setValue("Ошибка: " + e.message);
}
}
// 5. Извлечение всех ссылок
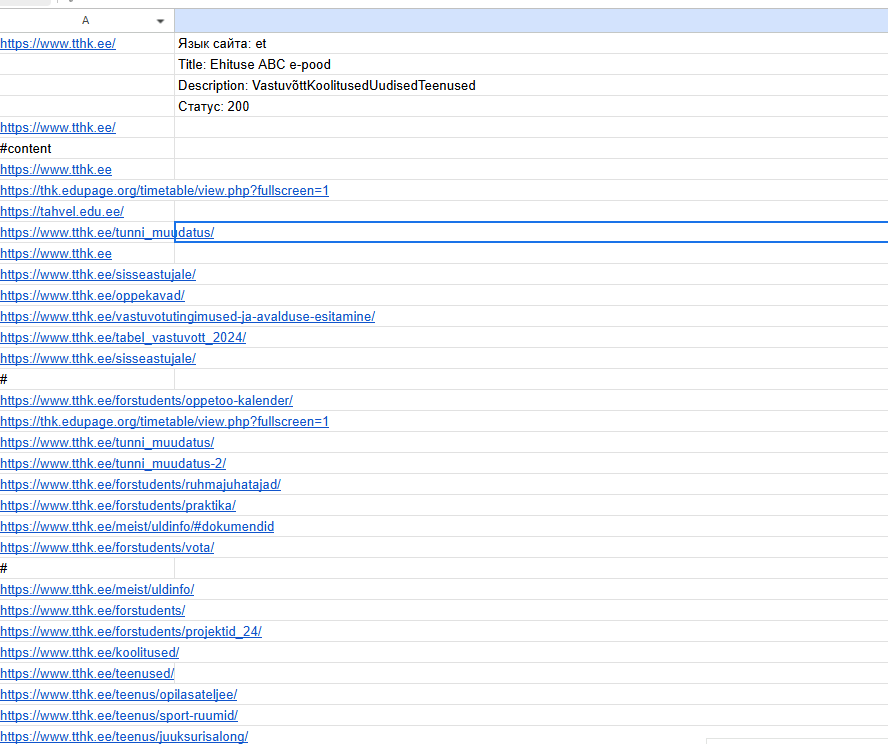
function extractAllLinks() {
const url = SpreadsheetApp.getActiveSheet().getRange("A1").getValue();
const html = UrlFetchApp.fetch(url).getContentText();
const links = [...html.matchAll(/<a[^>]+href=["']([^"']+)["']/gi)].map(m => [m[1]]);
if (links.length > 0) {
SpreadsheetApp.getActiveSheet().getRange(6, 1, links.length, 1).setValues(links);
} else {
SpreadsheetApp.getActiveSheet().getRange("A6").setValue("Ссылки не найдены");
}
}